決定木をフルスクラッチで書けるようになろう (CART)
この記事は慶應理工アドベントカレンダー2021の18日目の記事です.
昨日の記事はこちら.
アドカレに誘ってくださった @ainnoooさんがほんわかタイトルの記事書いてます. ちゃんとソケットあたりのコード読んでてすごい.
はじめに
改めまして. 研究室配属が決まって一安心しているJ科B3のYuWdです.
久しぶりに何か書いてみようということでアドカレに登録したものの, 怠惰ゆえに当日18日目(2:00AM)から書き始めております. アホです.
あまり時間がないので, 個人的にタイムリーなことを書きたい.... ということで, 研究室の面接で提出したコードをそのまま流用する形で, 「決定木」についての記事を書いていきたいと思います.
本記事の目的
本記事では二分木ベースのCARTについて説明します. ID3やC4.5など, 多分木ベースの決定木は扱いません.
対象となる読者は, 決定木のことをよく知らない人や, 一度もフルスクラッチで実装したことない人を想定しています.
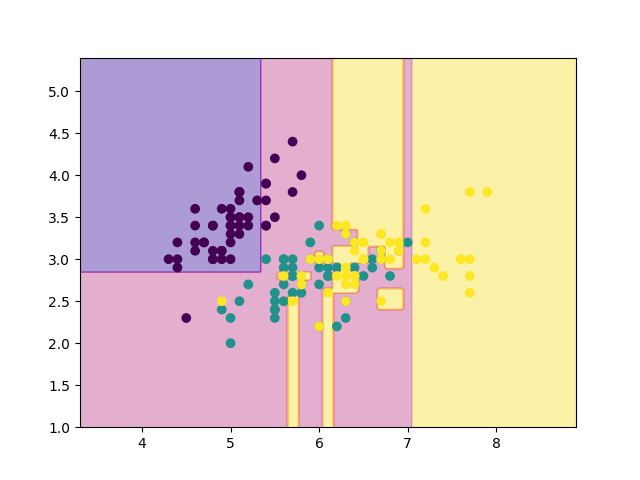
読者の目標は, 決定木(CART)の概要を理解し, 実際にnumpyだけで実装できるようになることです. この記事を理解すれば, 以下のような結果を生成する決定木をソラで書けるようになることでしょう.
本記事では, 以下の項目を扱います.
- 空間の分割
- 木の剪定とCV
- グリッドサーチによるハイパーパラメータの調整(ただの全探索)
本記事を読むのに必要な知識を以下に箇条書きで示しておきます.
- 高校程度の数学力
- numpyの扱い方
- 木に対する基礎的な理解
- DFS
注: 今回, pandasは扱いません. pandasは使い方を誤るとかなり重たくなってしまうので要注意です.
決定木とは
決定木といえば, 下のようなイメージが頭の中に立ち上がるかもしれません.
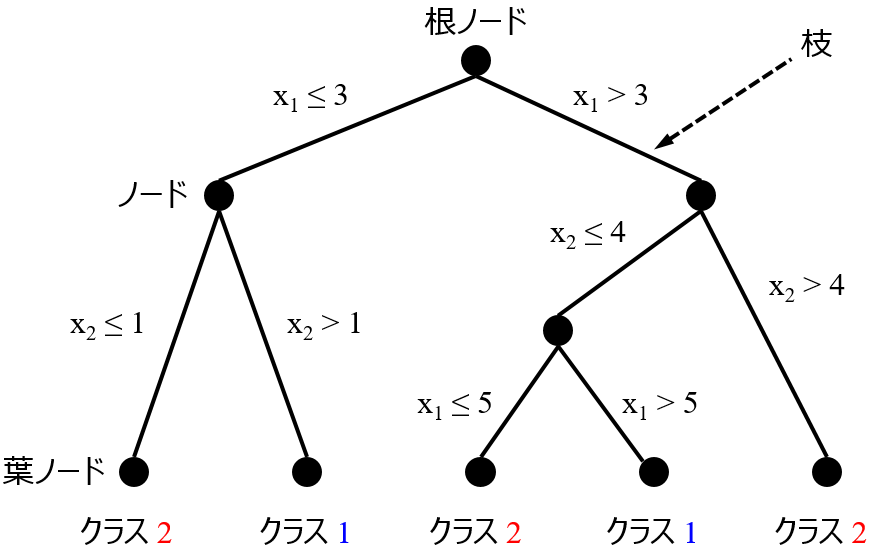
こうした「木の形」が頭にあると, どうしても決定木という手法が摩訶不思議なものであるかのように見えてきます.
ですが, 実際のカラクリは至極単純なものです. 簡単のため, まずは2つの特徴量 を扱うモデルを考えてみましょう.
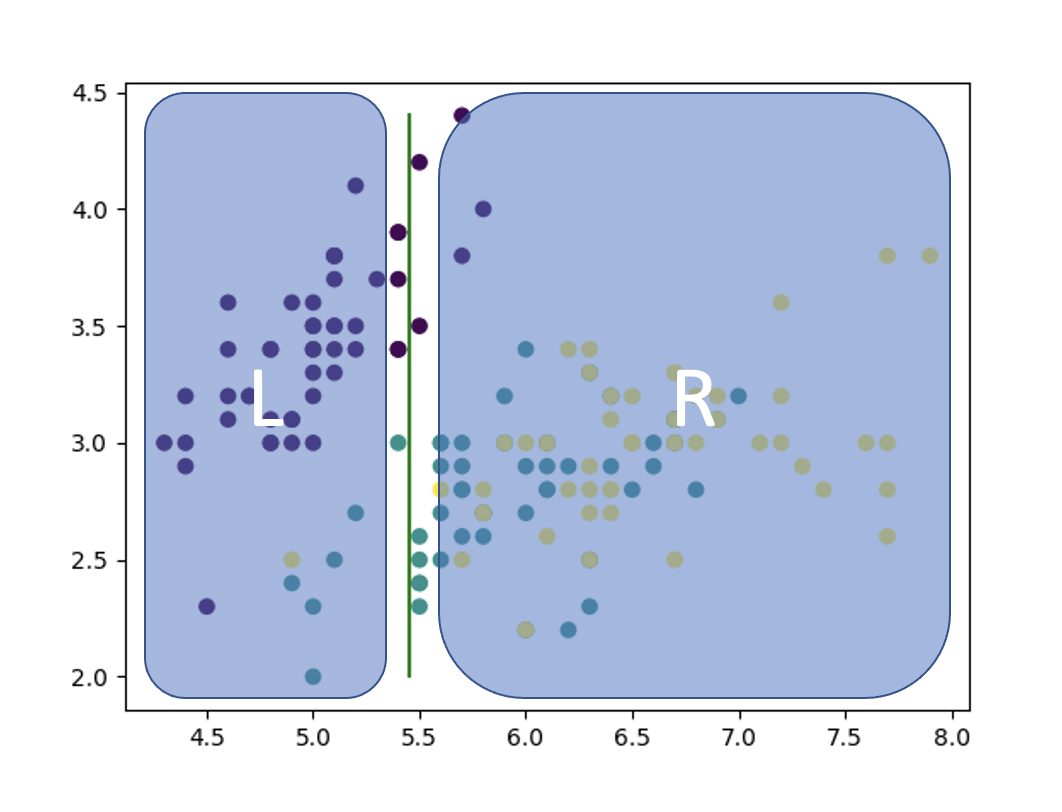
下に示すのは, sklearn.datasetsのirisのデータセットを2次元上にプロットしたものです. 横軸を, 縦軸を
とします.
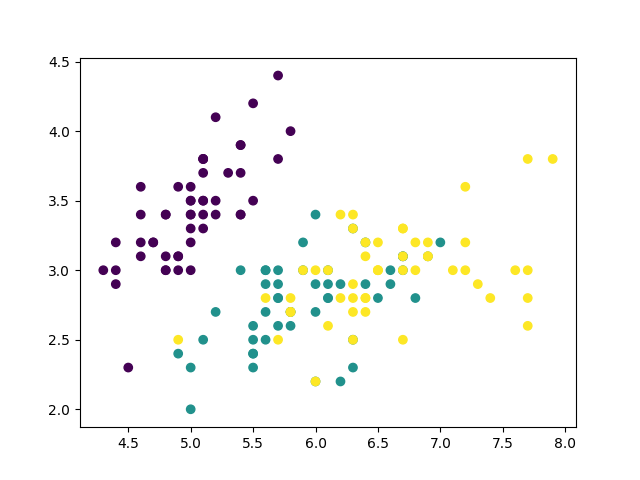
上の画像を眺めながら, このデータセットに対する識別器として, 有効かつ最も単純なモデルはどのようなものか考えてみてください.
NN系の手法やSVM(+カーネル法)が頭をよぎる人もいるかもしれません. しかし, これらの手法は一般に, 非線形関数を用いてゴニョゴニョする輩たちです.
回帰やパーセプトロンのような手法が想起される方がいらっしゃるかもしれませんね. しかし, これら以上に単純な発想の方法があるのです.
有効かつ最も単純な手法とは何か. それは, 各データ点をいい感じに分割できるように長方形をいっぱい作ることです.
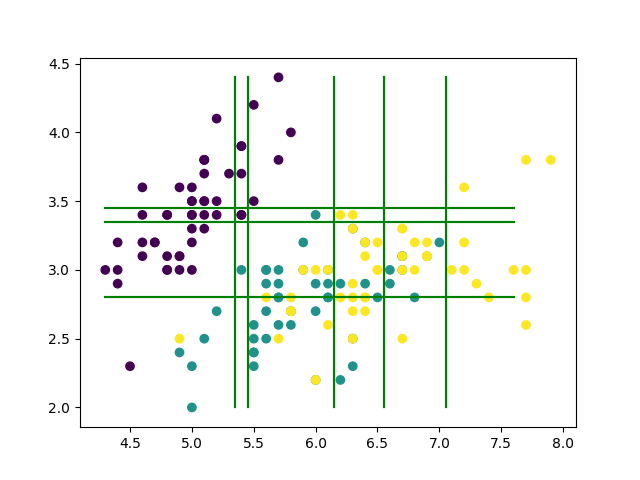
つまり, 2次元平面であれば上の画像のように, 特徴量 ごとに直線を引いていき, 領域をいい感じに分割していけば良いのです.
この考え方を 次元(特徴量
個の場合)に拡張しましょう.
すなわち, 決定木とは「
次元空間上に
次元の超平面を多数生成し, 分割領域を分けて識別器を表現(記述)する」手法なのです.
では実際, どのように空間を分割すれば良いのでしょうか.
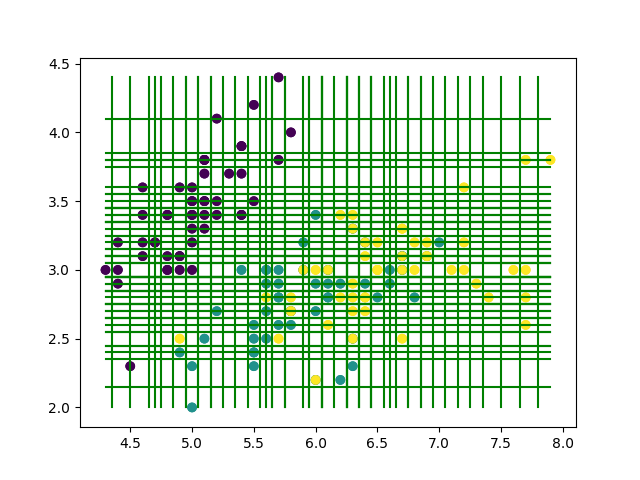
軸(=特徴量)の選択に関しては, 適当な順番で巡回させれば良いですから,
今回は と選択することとして, まずは以下のように分割すれば良いことがわかります.
- 軸
を選択 (
)
- 各データを
- 隣接点同士の中点を計算し, その中点を分割点の候補とする.
- 何らかの評価基準で分割点を評価する.
問題は, 4番目の「何らかの評価基準で分割点を評価する」方法です.
問いを整理する
問題に取り組む前に, まずは問いと設定を整理しましょう.
今回は, 特徴量 個で, クラスが
個 (
)のデータが与えられたとき, それらのクラスを識別する決定木を考えます.
ノードの分割は, 領域の分割と同等の関係にありますから, 木の深さごとに, 分割対象の軸が(
)と巡回していきます.
またノードを分割する規則として, 必ず左ノードは小なりイコール, 右ノードは大なりを意味することにします.
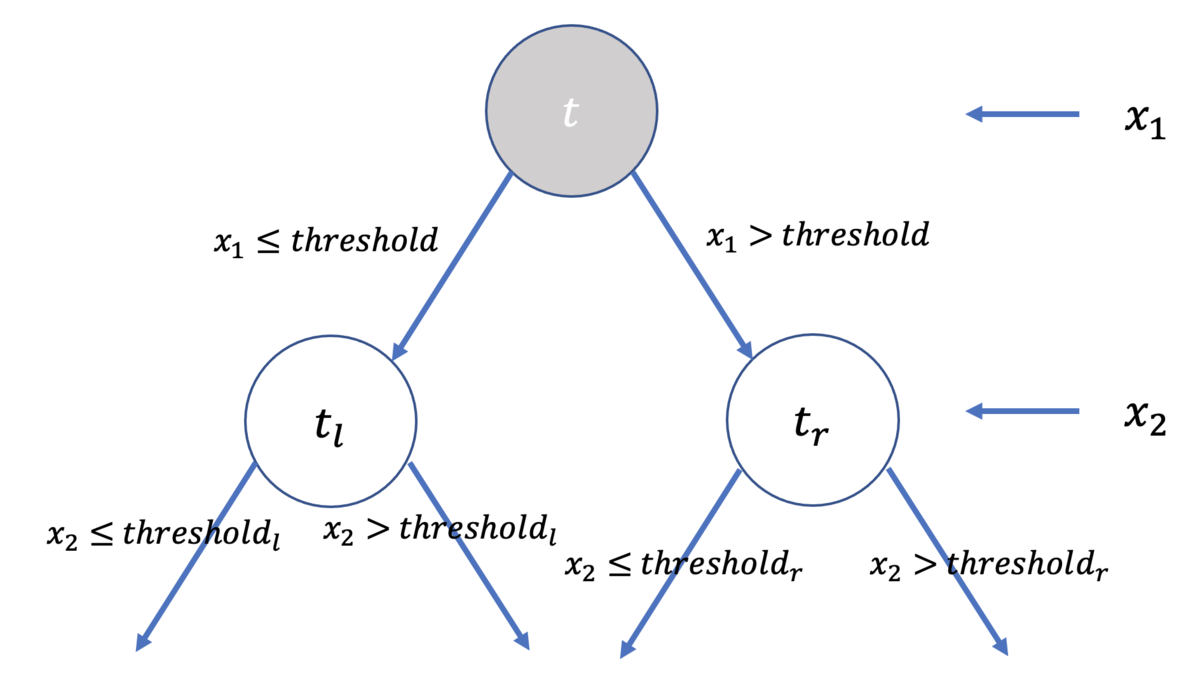
を分割
私達が直面している問題は, 上図における を如何に定めるべきなのか, ということなわけです.
不純度: 「如何に分割するか?」
ノード をノード
,
とに分割する場合を考えてみましょう.
以下に示すのは, ノード
を分割する様子です. 左側で示した決定木は, 右側のように分割されていることと対応します.
をノード
,
に分割
分割点を評価するにはどうすれば良いでしょうか. こういうときは極端な例を考えてみると感覚がつかめることが多々あります.
まず, 完全に分割された状態を考えてみると, ある分割領域に着目したとき,
内にあるデータ点のクラスが一つだけの状態が最も好ましい状況です. では逆に, 最も好ましくないのはどのような状態か. それは,
内にあるデータ点のクラスが最もバラバラな場合, すなわち,
内部にクラス
全てのデータが均等に入っている状態です.
CARTでは分割点を評価する基準として「不純度」(Impurity)と呼ばれる指標を扱います.
不純度 が
と表されるとき,
は, 上での議論の通り, 以下のような条件を満たせば良いことがわかります.
ならば,
が
.
ならば,
.
の順序に依存しない.
代表的な不純度には以下の3つがありますが, CARTでは主にジニ係数を使います.
- ノード
における誤り率
- ノード
- ノード
それぞれの式の意味は, ぐっと睨めば理解できると思います.
ジニ係数の意味するとこがよくわからない人は, 次のように考えると良いでしょう.
すなわち, ノード と対応する分割領域
において, クラス
に着目したとき,
以外のクラスのデータがその分割領域にどれだけ入っているかを, 全ての
について計算・総和することで, 分割領域
がいかにpureではないかを評価しています.
以上より, ノード を分割するには, 各分割点の候補についてそれぞれ不純度
を計算し, 不純度
が最も小さい候補点を採用してあげれば良いことがわかります.
具体的に, CARTでは以下のように行います.
個のデータ点に関して, それぞれ隣接するデータ点との中点を候補点とする. (候補点は
個できる)
が最も大きくなる候補点を採用する.
- その点を
として領域を分割.
ただし, とは, それぞれ左ノード, 右ノードに含まれるデータ数の比率(濃度)を指します.
すなわち,
として, 不純度に重みをつけてあげるのです.
木を成長させてみよう
これで大方決定木のことが理解できたはずなので, やっと実装できそうです.
まずは, ノードを表現するNodeを用意しましょう. X, Yはそれぞれ, 特徴量行列と目的変数のベクトルです.
import numpy as np import matplotlib.pyplot as plt import time PLOT = 1 class Node: # 決定木のノード def __init__(self, X, Y, depth=0): self.left = None self.right = None self.feature = None self.threshold = None self.X = X self.Y = Y self.features = [i for i in range(np.shape(X)[1])] self.depth = depth self.class_table = np.bincount(Y) self.class_label = np.argmax(self.class_table) # arg{max{count(x)}}
次に, 決定木を表現するTreeを用意しましょう.
class Tree: # 決定木 def __init__(self, X, Y, max_depth): self.root = Node(X, Y) self.X = X self.Y = Y self.max_depth = max_depth min_max_table = [] for i in range(np.shape(X)[1]): min_max_table.append([min(X[:,i]), max(X[:,i])]) self.min_max_table = min_max_table def gini(self, pair): # ジニ係数を計算 if sum(pair) == 0: return 0.0 probabilities = pair / sum(pair) gini = 1 - sum(probabilities**2) return gini def get_mean_array(self, x): # 各中点を計算 if len(x) == 0: return [] return np.convolve(x, np.ones(2), mode="valid") / 2 def get_gini(self, X, Y, feature=None, value=None, separate_type=None): # 分割後のジニ係数を計算 if separate_type == None: count_table = np.bincount(Y) elif separate_type == "left": count_table = np.bincount(Y[X[:, feature] <= value]) elif separate_type == "right": count_table = np.bincount(Y[X[:, feature] > value]) count = sum(count_table) half_gini = self.gini(count_table) return count, half_gini def split(self, node): # 適切な分割点を探索 X, Y = node.X, node.Y _, gini = self.get_gini(X, Y) maximum = -1 best = None threshold = None for feature in node.features: if len(np.unique(X[:, feature])) <= 1: continue ix = X[:, feature].argsort() mean_array = self.get_mean_array(np.unique(X[ix, feature])) for value in mean_array: # 各中点で分割してジニ係数を計算 lcount, lgini =\ self.get_gini(X[ix], Y[ix], feature, value, "left") rcount, rgini =\ self.get_gini(X[ix], Y[ix], feature, value, "right") count = lcount + rcount l_probability = lcount / count r_probability = rcount / count gain = gini - (l_probability * lgini + r_probability * rgini) assert gain >= 0 if gain > maximum: # chmax best = feature threshold = value maximum = gain if best is None: assert len(np.unique(X[:, feature])) <= 1 return (best, threshold) def fit(self): # 決定木を生成 self.grow(node=self.root) def grow(self, node): # node以降で木を成長させる if node.depth >= self.max_depth: return X, Y = node.X, node.Y feature, threshold = self.split(node) if feature is None: return node.feature = feature node.threshold = threshold il, ir = X[:, feature] <= threshold, X[:, feature] > threshold ndepth = node.depth + 1 node.left = Node( X[il], Y[il], depth=ndepth, ) node.right = Node( X[ir], Y[ir], depth=ndepth, ) self.grow(node.left) self.grow(node.right) def draw(self): # 分割区間をグラフに表示 if not PLOT: return stack = [self.root] terminals = [] while len(stack): # DFS current = stack.pop() if current.left is not None: stack.append(current.left) if current.right is not None: stack.append(current.right) if current.feature is None: continue if not current.feature: plt.plot([current.threshold, current.threshold], self.min_max_table[~current.feature], color="green") else: plt.plot(self.min_max_table[~current.feature], [current.threshold, current.threshold], color="green") def predict(self, X): # 識別器 predictions = np.zeros_like(X[:,0]) for i,x in enumerate(X): values = {} for feature in self.root.features: values.update({feature: x[feature]}) current = self.root while current.depth < self.max_depth and current.feature is not None: next = current.left if values[current.feature] < current.threshold else current.right if next is not None: current = next else: break predictions[i] = current.class_label return predictions
最後に, irisのデータセットを丸々使って学習させてみましょう.
def main(): from sklearn.datasets import load_iris # Data-set iris = load_iris() X, Y = iris.data[:, :2], iris.target # Train & Test tree = Tree(np.array(X), np.array(Y), max_depth=100) tree.fit() error = test(X, Y, tree) # Plot & Draw plt.scatter(X[:, 0], X[:, 1], c=Y) tree.draw() plt.savefig("result.png") print("error:", round(error, 3)) # 再代入誤り率 if __name__ == "__main__": start = time.time() main() elapsed_time = time.time() - start print("time:{:.2f}[sec]".format(elapsed_time))
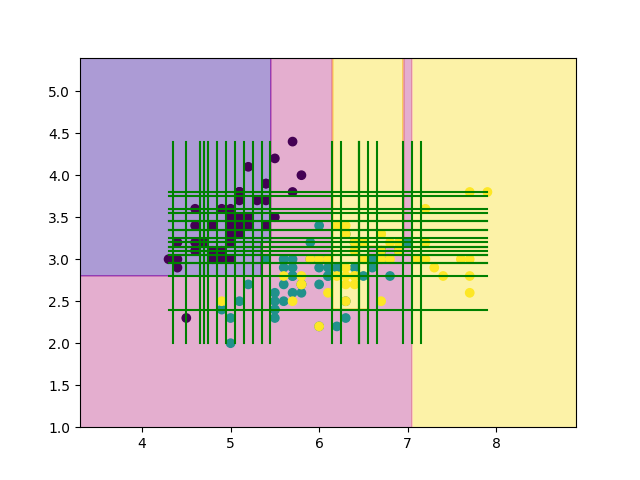
上の結果を見てみると, 確かにきちんと分割されていそうです!!
木の剪定
賢明なみなさんであれば, 先程の結果を見て, 汎化性能が極端に悪そうなことに気がつくと思います.
どうすれば汎化性能が向上するでしょうか. max_depthをイジれば簡単に済むのですが, 実は少しだけ面白い手法があるんです.
ということで,次は「木の剪定」について説明していきます.
木の剪定とは, その名の通り, 適切なエッジを切り取って枝刈りすることを意味します. 木が複雑すぎるならば, 何かしらの基準でエッジを評価し, それを切り取ってしまえば良いのです.
ここで, いくつか重要な記号と式を導入します.
非終端ノード
とする.
終端ノードの集合を
とする.
終端ノード
- 任意のノード
- 木全体の誤り率は
木を剪定する基準はどのようなものが考えられるでしょうか. まずは感覚的に考えてみましょう.
木を剪定するときは, なるだけ複雑で誤りが大きくなるような部分木を削除したくなりますから,
が最小なノード について, その部分木を全て削除してしまえば良いことがわかりますね.
ただし, 最低一つは終端ノードが存在することが前提ですので, 式を以下のように修正しましょう.
これで, 上式は必ず最低一つの終端ノードを持つことを加味して評価することになります. ということで, これっぽい式を頑張って導出しましょう. (以下, はじパタを参考にします.*2 )
まずは終端ノードの数にペナルティを課すことを考えます.
すなわち, 正則化パラメータ を用いて, ノード
における評価関数
を
と,
また, 木全体における評価関数
を
と
定義します.
ここで, 正則化パラメータ を大きくしていくことを考えてみると,
次第に
と
は互いに近づいていき, やがて同じ値となることがわかります.
このとき, 正則化パラメータ は
となり, あら不思議. 今さっきの式と同じものが得られました.
はじパタではこの を
ノード におけるリンクの強さと呼んでいます.
以上より, 次のようなアルゴリズムで木を剪定していけば良いこととなります. すなわち,
を満たすノード を探索し, 該当ノード
より下のものは全て削除します.
(はてなブログってargmin使えないの????)
剪定アルゴリズムが定まりました. では, 実装してみましょう.
ノードの探索ですが今回はDFSでやってみます.
## Node内 def get_error(self): # 1 - max{P(C_i|node=self)} table = self.class_table return sum(table) > 0 if 1 - max(table) / sum(table) else 1
## Tree内 def prune(self): # 木の剪定 (arg{min{g(x)}}の子孫を全て削除する) stack = [self.root] N = len(self.X) INF = 1 << 30 mg = (INF, None) # min_g, arg{min_g} while len(stack): # DFS current = stack.pop() has_left = current.left is not None has_right = current.right is not None is_terminal = not has_left and not has_right if not is_terminal: # 非終端ノードはg(node)を計算 expr = self.g(current) if expr < mg[0] and current != self.root: mg = (expr, current) if has_left: stack.append(current.left) if has_right: stack.append(current.right) alpha, target = mg if target is not None: target.left = None target.right = None return alpha def get_terminal_error(self, node): # 終端nodeの誤り率 = M(t) / N , M(t):=総誤り数 N = len(self.X) failure = 0 for y in node.Y: failure += y != node.class_label return failure / N def get_nonterminal_error(self, node): # 非終端nodeの誤り率 = 再代入誤り率 * 周辺確率 p_t = len(node.X) / len(self.X) # 周辺確率 R_t = node.get_error() * p_t return R_t def g(self, node): # g(t) = node_tのリンクの強さ R_t = self.get_nonterminal_error(node) stack = [node] terminals = 0 R_T = 0 while len(stack): # DFS current = stack.pop() has_left = current.left is not None has_right = current.right is not None if has_left: stack.append(current.left) if has_right: stack.append(current.right) if not has_left and not has_right: R_T += self.get_terminal_error(current) terminals += 1 alpha = R_t - R_T alpha /= (terminals - 1) return alpha
動かしてみよう
最終的なNodeとTreeは以下のようになります.
class Node: # 決定木のノード def __init__(self, X, Y, depth=0): self.left = None self.right = None self.feature = None self.threshold = None self.X = X self.Y = Y self.features = [i for i in range(np.shape(X)[1])] self.depth = depth self.class_table = np.bincount(Y) self.class_label = np.argmax(self.class_table) # arg{max{count(x)}} def get_error(self): # 1 - max{P(C_i|node=self)} table = self.class_table return sum(table) > 0 if 1 - max(table) / sum(table) else 1
class Tree: # 決定木 def __init__(self, X, Y, max_depth): self.root = Node(X, Y) self.X = X self.Y = Y self.max_depth = max_depth min_max_table = [] for i in range(np.shape(X)[1]): min_max_table.append([min(X[:,i]), max(X[:,i])]) self.min_max_table = min_max_table def gini(self, pair): # ジニ係数を計算 if sum(pair) == 0: return 0.0 probabilities = pair / sum(pair) gini = 1 - sum(probabilities**2) return gini def get_mean_array(self, x): # 各中点を計算 if len(x) == 0: return [] return np.convolve(x, np.ones(2), mode="valid") / 2 def get_gini(self, X, Y, feature=None, value=None, separate_type=None): # 分割後のジニ係数を計算 if separate_type == None: count_table = np.bincount(Y) elif separate_type == "left": count_table = np.bincount(Y[X[:, feature] <= value]) elif separate_type == "right": count_table = np.bincount(Y[X[:, feature] > value]) count = sum(count_table) half_gini = self.gini(count_table) return count, half_gini def split(self, node): # 適切な分割点を探索 X, Y = node.X, node.Y _, gini = self.get_gini(X, Y) maximum = -1 best = None threshold = None for feature in node.features: if len(np.unique(X[:, feature])) <= 1: continue ix = X[:, feature].argsort() mean_array = self.get_mean_array(np.unique(X[ix, feature])) for value in mean_array: # 各中点で分割してジニ係数を計算 lcount, lgini =\ self.get_gini(X[ix], Y[ix], feature, value, "left") rcount, rgini =\ self.get_gini(X[ix], Y[ix], feature, value, "right") count = lcount + rcount l_probability = lcount / count r_probability = rcount / count gain = gini - (l_probability * lgini + r_probability * rgini) assert gain >= 0 if gain > maximum: # chmax best = feature threshold = value maximum = gain if best is None: assert len(np.unique(X[:, feature])) <= 1 return (best, threshold) def fit(self): # 決定木を生成 self.grow(node=self.root) def grow(self, node): # node以降で木を成長させる if node.depth >= self.max_depth: return X, Y = node.X, node.Y feature, threshold = self.split(node) if feature is None: return node.feature = feature node.threshold = threshold il, ir = X[:, feature] <= threshold, X[:, feature] > threshold ndepth = node.depth + 1 node.left = Node( X[il], Y[il], depth=ndepth, ) node.right = Node( X[ir], Y[ir], depth=ndepth, ) self.grow(node.left) self.grow(node.right) def prune(self): # 木の剪定 (arg{min{g(x)}}の子孫を全て削除する) stack = [self.root] N = len(self.X) INF = 1 << 30 mg = (INF, None) # min_g, arg{min_g} while len(stack): # DFS current = stack.pop() has_left = current.left is not None has_right = current.right is not None is_terminal = not has_left and not has_right if not is_terminal: # 非終端ノードはg(node)を計算 expr = self.g(current) if expr < mg[0] and current != self.root: mg = (expr, current) if has_left: stack.append(current.left) if has_right: stack.append(current.right) alpha, target = mg if target is not None: target.left = None target.right = None return alpha def get_terminal_error(self, node): # 終端nodeの誤り率 = M(t) / N , M(t):=総誤り数 N = len(self.X) failure = 0 for y in node.Y: failure += y != node.class_label return failure / N def get_nonterminal_error(self, node): # 非終端nodeの誤り率 = 再代入誤り率 * 周辺確率 p_t = len(node.X) / len(self.X) # 周辺確率 R_t = node.get_error() * p_t return R_t def g(self, node): # g(t) = node_tのリンクの強さ R_t = self.get_nonterminal_error(node) stack = [node] terminals = 0 R_T = 0 while len(stack): # DFS current = stack.pop() has_left = current.left is not None has_right = current.right is not None if has_left: stack.append(current.left) if has_right: stack.append(current.right) if not has_left and not has_right: R_T += self.get_terminal_error(current) terminals += 1 alpha = R_t - R_T alpha /= (terminals - 1) return alpha def draw(self): # 分割区間をグラフに表示 if not PLOT: return stack = [self.root] terminals = [] while len(stack): # DFS current = stack.pop() if current.left is not None: stack.append(current.left) if current.right is not None: stack.append(current.right) if current.feature is None: continue if not current.feature: plt.plot([current.threshold, current.threshold], self.min_max_table[~current.feature], color="green") else: plt.plot(self.min_max_table[~current.feature], [current.threshold, current.threshold], color="green") def predict(self, X): # 識別器 predictions = np.zeros_like(X[:,0]) for i,x in enumerate(X): values = {} for feature in self.root.features: values.update({feature: x[feature]}) current = self.root while current.depth < self.max_depth and current.feature is not None: next = current.left if values[current.feature] < current.threshold else current.right if next is not None: current = next else: break predictions[i] = current.class_label return predictions
では, 試しに10回ほど剪定を行うようにmain関数をいじってみましょう.
def main(): from sklearn.datasets import load_iris # Data-set iris = load_iris() X, Y = iris.data[:, :2], iris.target # Train tree = Tree(np.array(X), np.array(Y), max_depth=100) tree.fit() # Pruning for _ in range(10): g = tree.prune() #Test error = test(X, Y, tree) # Plot & Draw (おまじない) mesh = 200 mx, my = np.meshgrid(np.linspace(X[:, 0].min()-1, X[:, 0].max()+1, mesh), np.linspace(X[:, 1].min()-1, X[:, 1].max()+1, mesh)) mX = np.stack([mx.ravel(),my.ravel()],1) mz = tree.predict(mX).reshape(mesh,mesh) plt.scatter(X[:, 0], X[:, 1], c=Y) plt.contourf(mx, my, mz, alpha=0.4, cmap='plasma', zorder=0) plt.savefig("result.png") tree.draw() plt.savefig("result_with_lines.png")
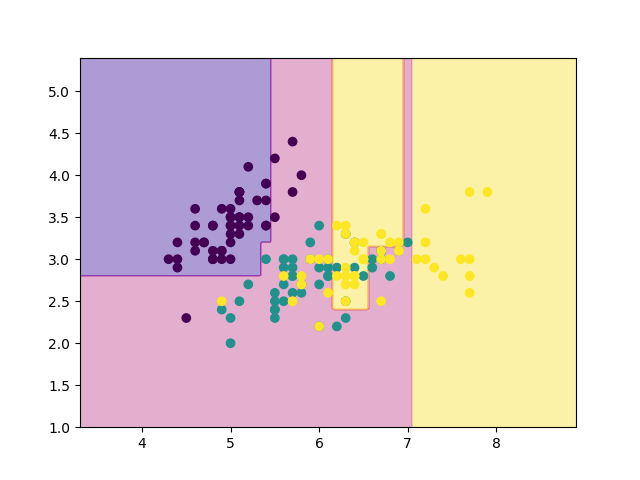
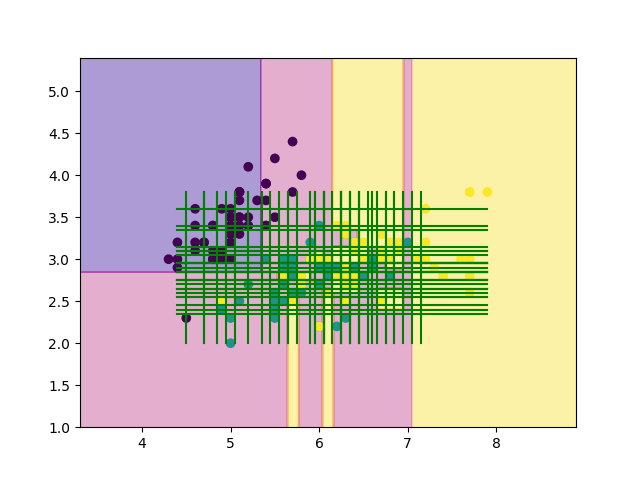
先程の結果と見比べてみると, 確かに領域が少しだけ荒くなっていますね. 再代入誤り率は19%でした.
ところで, 剪定回数はどのように決めれば良いでしょうか. はじパタによると, ホールドアウト法や交差検証法を行って決めるのが良いみたいです.
今回は交差検証を実際にやってみましょう. まずはデータを巡回しながら分割していく関数を書きます. こういうのは, ベクトル(行列)をconcatenateしてあげるとmod取らずに済むので便利です. (競プロの名残でやってるだけで, bestな方法かはよくわからないです)
def split_data(X, Y, size): # データを分割 window = len(Y) // size train_size, test_size = len(Y) - window, window res = [] _X, _Y = np.concatenate((X, X)), np.concatenate((Y, Y)) for i in range(size): offset = window * i test_tail = offset + window X_test, Y_test =\ _X[offset:test_tail], _Y[offset:test_tail] X_train, Y_train =\ _X[test_tail:test_tail + train_size], _Y[test_tail:test_tail+train_size] res.append((X_train, Y_train, X_test, Y_test)) return res
ついでに, モデルをテストするヤツも書きましょう.
def test(X_test, Y_test, tree, log=False): # モデルをテスト Xsubset = X_test res = tree.predict(Xsubset) allcount = len(Xsubset) correct = np.sum(res == Y_test) error = 1 - correct / allcount if log: print("all:", len(Xsubset)) print("correct:", correct) return error
あとは, 交差検証して適切な剪定回数を探索してあげるだけです. 今回は, グリッドサーチ(という名の全探索)を行いましょう. 大体, 0~20程度で剪定が終わってしまうことが多いです.
def main(): from sklearn.datasets import load_iris # Data-set size = 4 searched = [] iris = load_iris() X, Y = iris.data[:, :2], iris.target splited = split_data(X, Y, size) # Search-HyperParam models = {} for pruning_count in [i for i in range(20)]: models[pruning_count] = [] # Train & Test errors = 0 for i in range(size): X_train, Y_train, X_test, Y_test = splited[i] # Decision-tree tree = Tree(np.array(X_train), np.array(Y_train), max_depth=100) tree.fit() # Pruning!! for _ in range(pruning_count): g = tree.prune() error = test(X_test, Y_test, tree) models[pruning_count].append((error, tree)) errors += error tree.draw() plt.scatter(X[:, 0], X[:, 1], c=Y) plt.savefig("images/figure{}.png".format(pruning_count)) plt.clf() errors /= size print("{:.2f}, {}".format(errors, pruning_count)) searched.append((errors, pruning_count)) # Select-HyperParam searched.sort(key=lambda x: x[0]) error, pruning_count = searched[0] print("pruning_count:", pruning_count) # Select-model models[pruning_count].sort(key=lambda x: x[0]) error, tree = models[pruning_count][0] # Plot & Draw mesh = 200 mx, my = np.meshgrid(np.linspace(X[:, 0].min()-1, X[:, 0].max()+1, mesh), np.linspace(X[:, 1].min()-1, X[:, 1].max()+1, mesh)) mX = np.stack([mx.ravel(), my.ravel()], 1) mz = tree.predict(mX).reshape(mesh, mesh) plt.scatter(X[:, 0], X[:, 1], c=Y) plt.contourf(mx, my, mz, alpha=0.4, cmap='plasma', zorder=0) plt.savefig("result.png") tree.draw() plt.savefig("result_with_lines.png") r = test(X,Y,tree) print("error:", round(error, 3)) print("r:", round(r, 3)) if __name__ == "__main__": start = time.time() main() elapsed_time = time.time() - start print("time:{:.2f}[sec]".format(elapsed_time))
実行結果は以下のとおりです.
0.44, 0 0.43, 1 0.39, 2 0.41, 3 0.41, 4 0.41, 5 0.41, 6 0.41, 7 0.41, 8 0.41, 9 0.41, 10 0.41, 11 0.43, 12 0.49, 13 0.61, 14 0.61, 15 0.62, 16 0.66, 17 0.66, 18 0.66, 19 pruning_count: 2 error: 0.27 r: 0.153 time:19.07[sec]
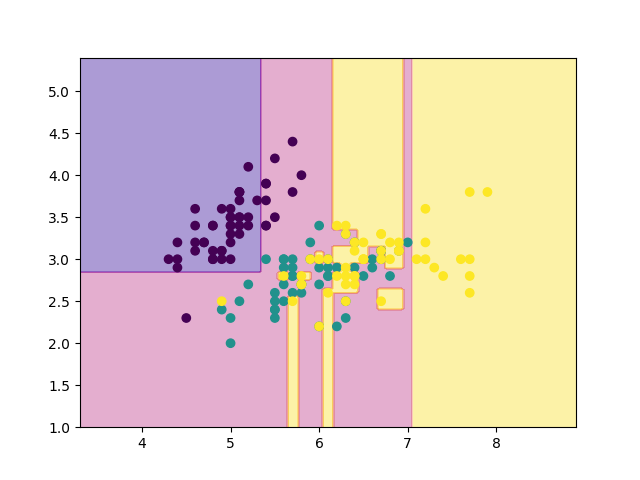
ということで, 結局今回のirisのデータセットでは, 剪定回数2回が最も良いモデルだと判断したようです. 再代入誤り率は15%でした.
iris以外のデータでも試してみよう.
同心円状に分布したデータで試してみましょう.
X = np.random.uniform(-1,1,[500,2]) Y = (np.sqrt(X[:,0]**2+X[:,1]**2)//0.2).astype(int)
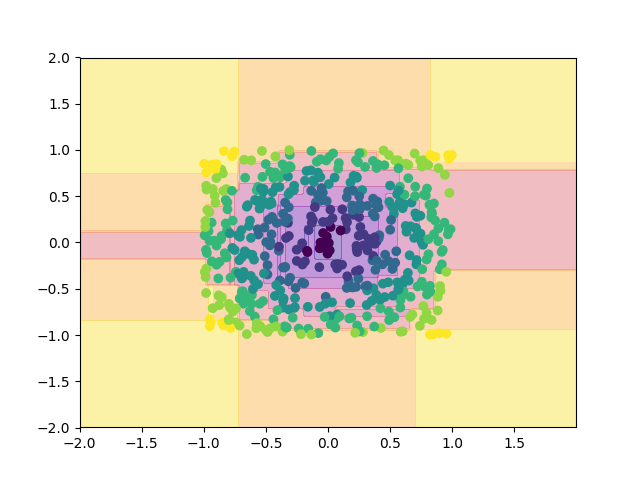
0.24, 0 0.65, 1 0.70, 2 0.70, 3 0.70, 4 0.70, 5 0.70, 6 0.70, 7 0.70, 8 0.70, 9 0.70, 10 0.70, 11 0.70, 12 0.70, 13 0.70, 14 0.70, 15 0.70, 16 0.70, 17 0.70, 18 0.70, 19 pruning_count: 0 error: 0.216 r: 0.054 time:52.92[sec]
あれれ. 剪定0回のモデルが採用されてしまいました.
かなり複雑な木が生成されているはずですから, 剪定回数0回では汎化性能が良いとは言えなそうです.
また上の実行結果を見てみると, 剪定回数 以降の精度がほとんど変化していません.
つまり, このような, 決定木では特徴を捉えにくいデータセットだと, 一度に大量のエッジを剪定してしまうというリスクがあることがこれらから読み取ことができます.
したがって実際はこのような手法ではなく, 先程登場した正則化パラメータ であったり, 木の深さ max_depth を調整して学習させるのがbetterな戦略のようです.
(時間の都合上書けませんでしたが, ランダムフォレストと呼ばれる手法を使うとより良い結果が得られます. 次回, 時間があればランダムフォレストについても記事を書いてみようと思います.)
おわりに
どうでしたか? これで決定木をソラで書けるようになりましたよね????????
決定木には, 深層学習とは異なる面白みがあります. あまり研究のネタにはならないようですが(失礼), KaggleのようなコンペではGBDTやLightGBMなど, 決定木ベースのモデルが使われることが多々あります.
ということで, 決定木もちょっとは勉強してみて損は無いかなと思います.
久しぶりに記事を書いてみたのですが, やはり書物は面白いです.
このアドカレを機に, ちょっとずつアウトプットの頻度を増やしていけたらいいなと思ってます. アドカレを主催した@yapatta_progさんありがとうございました.
コードはgistにあげておいたので, 自由にお使いください. ここおかしいよ〜ってなったら是非コメントかTwitterで投げてみてください!
【超具体的に】大学一年生としての2019年度を振り返る
こんにちは。
去年の春、僕は理工学部の一年生として慶應義塾大学に入学しました。
ですが、入学してすぐ、4月5月あたりでしょうか、僕は大学生としての自分のあり方、生き方に苦闘する日々を過ごしていました。というのも当時の僕は、大学受験という大きな壁を自分なりにも何とかぶち壊し、受験生の頃には肌で感じていた、前へと前進しているという明確な実感を欠いていたのです。
それはKPIを設定するなどという、具体的な定量性を求めていたというわけではありません。
むしろ、定性的なもの、具体的な到着地点のようなものがほしかったわけです。
僕は様々な格闘、思考の末、大学一年生としての生き方の指針のようなものを、こう結論付けることにしました。
「ひとまず色々吸収してから考えるか彡(゚)(゚)」
つまり、現状に対する判断を括弧に入れる、そういう結論に達したわけです。
正直言って苦闘対象に対する明確な解にはなっていません。
しかし、これは僕の大学生活にとって、とても重要なキーワードとなります。
(当時、ハイデガーに傾倒していた僕は、自分の成りたい理想像のようなものを欠いた状態でありながら常に死におびえ、とにかく前へ前へと前進する以外に自尊心を保つ手段がなかったのです。)
そのようにして僕は、吸収していったたくさん知識の追い風によって、思考が正しい軌道で渦を巻いていった、そんな実感を抱くようになります。
...いや、実はそれだけでは留まらず、正しく進んでいった思考の渦は、その軌道の先に隠されていた、生活の「ぼろ」をも掬い上げていきます。
(その話については、また今度機会があればします。デタッチメントとコミットメントに関わるお話です。)
とりあえず今回は、実際の僕の行動を列挙しながら、何を吸収したのか、何を考えてきたのかを軸に、どのようにこの1年間を過ごしたのかについて記述していこうと思います。
- 『なぜ1年を振り返るのか』~記憶の脆さとタイムスタンプ~
- 『履修指針』~如何に授業を選択するか~
- 『プログラミング』 ~5ヶ月で総スター130超~
- 『機械学習』~数学苦手が使った参考書~
- 『大学の授業』~何を吸収したか?~
- 『読んだ本』~ 少なく読み、多くを考える。~
- 寺田寅彦『寺田寅彦随筆集』
- Nir Eyal『Hooked』
- Peter Theil 『Zero to One』
- エリック・リース『リーンスタートアップ』
- 武藤滋夫『ゲーム理論入門』
- 村上春樹『夜のくもざる』
- 村上春樹『うずまき猫の見つけ方』
- 村上春樹『ランゲルハンス島の午後』
- 村上春樹『アフターダーク』
- 村上春樹『海辺のカフカ』
- 村上春樹『ダンス・ダンス・ダンス』
- 村上春樹『色彩を持たない多崎つくると、彼の巡礼の年』
- 村上春樹『風の歌を聴け』
- 村上春樹『村上春樹 雑文集』
- 星新一『きまぐれエトセトラ』
- 加藤典洋『村上春樹の短編を英語で読む』
- 船木亨『いかにして思考するべきか』
- 許成準『天才たちのライフハック』
- クレア ウィークス『不安のメカニズム』
- ロルフ・ドベリ『Think Clearly』
- エリック, ジョナサン, アラン『How Google Works』
- ヴォルターベンヤミン『複製技術時代の芸術』
- 掌田 津耶乃『Firebase入門』
- Pete Goodliffe『ベタープログラマー』
- 矢沢久雄『コンピューターはなぜ動くのか』
- オライリー出版『アルゴリズムクイックリファレンス』
- シェイクスピア『ハムレット』
- 石川啄木『一握の砂』
- 『終わりに』 ~ 局所解とB2 ~
『なぜ1年を振り返るのか』~記憶の脆さとタイムスタンプ~
2019年の年末、僕は絶望していた。 ー というのも、僕はこの一年何をしていたのか、何を遺してきたのか、自分でもよくわからなかったんです。僕はこの一年をとても無駄に過ごして来た、そんな気しかしなかった。
そこで僕は、手帳にこの一年間、自分がやってきたことをすべて書き上げてみた。すると、案外いろんなことをしているんですね、気づいてないだけで。
その時僕は、記憶の脆さと一年の総括の重要性に気づいたんです ー 「ああ、これは一年を綺麗にまとめておかないと、記憶からすぐに消えてしまうな」と。
というわけで、一年を振り返る記事を書くべきだな、と思い立ったわけであります。
また、この種の記事というものは、例えば大学卒業時に公開したのでは時すでに遅しで、実際に大学一年を終えてすぐに書き上げ、公開しなければ意味がありません。
要するに、タイムスタンプの押されたポートフォリオのようなものなわけですね。
ということで、大学1年生が終わってすぐのこの時期に書き上げました。
『履修指針』~如何に授業を選択するか~
大学生活が始まるとすぐに、履修登録があります。
僕は漫然と授業を取るのではなく、まずはどのように授業を選択するかについての指針を建てることにしました。
具体的には以下のような方針を策定していました。
- エグ単は最高一つまで
- 上記の一つ以外はすべて楽単と呼ばれるものを取る
- どうしても取りたいが、自分の負担になりそうな授業は"潜る"
このような方針を取った理由は以下5つになります。
- 慶應理工は必修が大変と聞いたので
- 大学生活がどんなものかまだわからないので
- 慶應理工は秋学期の履修を春に決めるのでリスクヘッジとして
- 慶應理工はGPAによって学科が決まるので
- 自分が怠け者であることを知っているので
何事もメタ的に見ることって大切ですよね
ちなみに、慶應理工の授業はそこまで大変ではなかったです。
『プログラミング』 ~5ヶ月で総スター130超~
2019年6月からSwiftとPythonを勉強し始めた
僕が思う一番の言語学習方法は、実際に何か作るターゲットを決めて、とりあえず作ってみることです。
そんなわけで、とりあえず思うままにアプリとライブラリをswiftで作っていきました。
作った順に紹介していきます。
ちなみにGithubの初Commitから5ヶ月くらいで僕のリポジトリは総スター数130以上獲得してます。たぶん頑張りました。

2019年6月からSwift勉強開始
Minerva: 板書管理アプリ
Swiftを触って一週間ちょいの頃、人生で初めて作ったiOSのアプリです。
大学の板書を自動でトリミングしてフォルダ管理によって整理するヤツ。
あまりに自己満足的、且つ学習目的だったのでソース・アプリ共に公開はしてないです。
ほぼでけた pic.twitter.com/KPprlj6fdz
— Yuiga Wada (@YuigaWada) 2019年6月23日
Tokui: チュートリアル用ライブラリ
Swift 学習後2週間で作りました。
前述のMinervaに組み込みたかった+とりあえず何か公開してみたかった+GitHubとはなんぞや?って感じだったので、gitの勉強とともにライブラリを作って公開することを決めました。
PolioPager: アニメーションタブ
アニメーションの知識が皆無だった当時の僕は、アニメーションの実装となると外部ライブラリを使ってばっかりでした。そんな僕でしたから、こういうアニメーションを実装したい!となると案外既存のライブラリでは対応しきれなかったりするわけです。
そんなわけで、アニメーションの勉強とともに、SNKRS風のタブを実装するライブラリを作りました。
2019年の8月中旬くらいから8月末くらいで作り上げたと思います。
CallSlicer: AppleWatchにLINE通話の通知を促すtweak
Appleの仕様上、AppleWatchはiPhoneが受信するLINE通話の通知を受け取ることができません。僕は昔からJailbreakに詳しかったので、この弱点を克服するtweakくらい俺でも作れるのでは?と思い立ち作ってみました。
Objective-Cは書いたことがなかったのですが、英語の記事やら他のdeveloperのソースなどをいろいろ読み漁ったら、普通に作ることができて少し自信がついたのを覚えてます。
ごにょごにょiPhoneのログを確認しながら、ごにょごにょコードを書いていったら、いつの間にかLINE通話の通知をAppleWatchに横流しするtweakの完成です。
iCimulator: カメラのエミュレーション
iOS Simulatorは本来、カメラ機能のシミュレーションができません。
そこで、そのカメラ機能をエミュレートするライブラリを作りました。
かなり実験的で挑戦的なライブラリとなってます。興味本位で作ったので、実用性はないと思われます。
RealCodeDay: Fuck CodeDay!!!!
コードログとかいうクソサイトを迂回するためのChrome拡張です。
技術的に解決できる日々のヘイトは誰かが技術的に解決してあげるべきです。
てなわけで、
海外サイトをただ翻訳しただけの害悪なサイト”コードログ(CodeDay)”のページから一瞬で翻訳元に飛べるchrome拡張、RealCodeDayを作りました。
MisskeyKit: MisskeyAPIのラッパー
Misskeyという分散型SNSのAPIをSwiftでラッピングしたものを作りました。
単純に誰もラッパーを書いていなかったので、僕が書くか〜って感じのゆるーい動機で作りました。作っていて、すごい楽しかった記憶があります。
YanagiText: 任意のUIViewをTextViewにぶちこむ
Misskeyのクライアントを作っているのですが、どうしてもこれが必要だったので自分で作りました。
任意のUIViewをTextViewにぶちこむことができます。
MissCat: MisskeyのiOSクライアント
MisskeyのiOSクライアントがまだこの世に存在していないので、じゃあ僕が作るか〜って感じで現在進行系で作ってます。
MVVM実装ですが、コード汚いので、もしかしたらOSSにはならないかもしれないです。
最近作ってるiOSのMisskeyクライアント🎉
— Yuiga Wada (@YuigaWada) 2019年12月4日
RxSwiftによるMVVM実装です
prmlに追われて最近全然進捗産んでないけどね pic.twitter.com/hB2Me4oJ42
Swiftの勉強について
基本的にはネットと本1冊で頑張りました。
特にQiitaや、Swiftに関してまとめてくれてる英語の記事、Stack Overflowがとても役に立ちました。
Swift実践入門
Swiftの独特な雰囲気を掴むためにこれを一通り読みました。
目次でさーっと確認して、自分が知らないとこ、曖昧になっているところをちょこちょこ読んでいく、という感じです。
![[改訂新版]Swift実践入門 ── 直感的な文法と安全性を兼ね備えた言語 (WEB+DB PRESS plus)](https://images-fe.ssl-images-amazon.com/images/I/51WsZJ6wtIL._SL160_.jpg "[改訂新版]Swift実践入門 ── 直感的な文法と安全性を兼ね備えた言語 (WEB+DB PRESS plus)")
『機械学習』~数学苦手が使った参考書~
昔からMLを勉強したいと思っていたので、春ごろからちょこちょこ本を読んで頑張りました。
こちらも読んだ順に紹介していきます。
実践 DeepLearning
理論がスッカスカで、説明も翻訳も微妙で、正直全体的にうーんって感じでした。
ですが、当時MLとはなんぞやDeepLearningとはなんぞや、CNNとか聞いたことない!っていう僕にとっては、機械学習の全体マップのような役割を果たしてくれていたのかもしれません。
")
実践 Deep Learning ―PythonとTensorFlowで学ぶ次世代の機械学習アルゴリズム (オライリー・ジャパン)
- 作者:Nikhil Buduma
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/04/26
- メディア: 単行本(ソフトカバー)
PRML(パターン認識と機械学習)
KCSというサークルにお邪魔した時に先輩から教えてもらった本です。
大学1年の夏休み、2章あたりで発狂してPRML挫折しました。(それはそう)
当時を思い返せば、とりあえずベイズ統計から勉強しないと、ということで日吉駅の本屋に行って次に紹介するベイズ統計の本を買いに行きましたね...
ちなみに、PRMLは秋学期に輪講があって、その輪講ですごい進捗を生みました。
上巻は5章の後半を除いて大体一周はできたと思います。

身につくベイズ統計学
背伸びして難しい本を買っても逆に自分を圧迫するだけだ、と思いなるべくわかりやすくすぐに読めるような本を選びました。
MAP推定と最尤推定の違いも実感として微妙だった当時の僕にとっては、とても役に立った一冊だったと思います。
(今となれば致命的なまでに知識不足、演習不足だったと思う)
")
わかりやすいパターン認識
やさしい理系数学、的なノリの本です。
でもPRMLに比べたら全然読みやすいし、助かりました。そして普通におもしろい!
普通に2周程度回しました。
")
必要な数学だけでわかる ニューラルネットワーク
ニューラルネットワーク全体を俯瞰して見れる本を探していて、日吉図書館で見つけた本です。自分の知識が整理されていく感覚を感じました。

必要な数学だけでわかる ディープラーニング
こちらも、同じ日に借りたものです。こちらはもっと実装寄りで面白かったです。

C++で学ぶディープラーニング
これはまだ読んでる最中ですが、PythonではなくC++で実装しているところに惹かれて図書館で借りました。GPU剥き出しな感じの実装が書いてあっておもしろいです。

『大学の授業』~何を吸収したか?~
僕は真面目ではないので、1限と2限は大学に行きません。なので、不真面目な輩が書いた、信頼性にかける授業レビューって感じで読み進めてください。
現代社会論
ヒロシマ・ナガサキの被爆体験という観点から、ウィトゲンシュタイン的に言えば「語り得ないもの」について如何に言語化し、如何に記録していくのか、そういう議論を追求する授業です。
聞き手と語り手の相互作用によってインタビューを再構築していくという、構造主義的な方法論をとり、語り手の感情を自己の体験と織り交ぜて追体験していくという手法がとても新鮮でおもしろかった。
つい先日、いつも履き慣らしているDr. Martensを磨いていると、靴の傷痕がトリガーとなって、当時付き合っていた彼女のこと、この靴を履いて受けに行った入試試験のこと、それから旅行先の思い出とかが、ありありと眼前に蘇ってきて、この授業で教授が仰ってた"記憶の外部性"という考え方を体現したのを皮切りに、とても思い出深い授業となりました。
地球科学概論I
地球科学についての般教です。
ハワイが日本方向へ移動する速度が人間の爪や髪が延びるスピードと同じくらい、というほんの些細な豆知識レベルのお話から、大陸の出現、大陸の一生(ウィルソンサイクル)、超大陸の話といった、地球レベルのお話、さらには宇宙と地球の関係性など、宇宙レベルのお話などもあっておもしろかったです。
情報学基礎
教授の話がつまらなかったので、ひたすら教科書を読んでました。
この授業って本当に必要なのでしょうか。テストは持込可のただのクイズ大会で、授業もペラペラな内容ばかり。正直言って、情報学とは名ばかりで、ただただ形骸化しただけのクソ授業だと思ってます。
自然科学実験
高校がFランだったので実験なんてほとんどしたことがなく、とても新鮮で面白かったです。特に、自分の知ってる化学現象、化学的知識が実際に目の前で起きているという事実がとても胸に響きました。
あと、実験結果に対して自由に考察させてくれるので、とても楽しかったです。
ちなみに実験自体はそこまで楽しくはない。
中国語
クソ。
数学II (線形代数)
普通に線形代数は面白いです。
基本的に授業は聞かず自分で教科書とにらめっこしてたのですが、慶應の教科書はとても質が良い気がします。
授業に関しては、もうちょっと証明とかにも時間を割いてもいいんじゃないの?とは思った。
物理学
授業行ってないけど、単位は来るので良い。
僕、まあまあ物理好きなんですけど、慶應の物理の試験は形式がホントに残酷?なので形式はマジで変えたほうがいいと思ってます...
理工学概論
この授業は、例えば、理科大在学中に日本最大(?)の化学系webサイトを作った教授の人生論だとか、偉大な研究成果を挙げている教授の、研究成果を獲得するための方法論であったりとか、読みやすい日本語とはどのような日本語のことを指すのか、とか、そういったとても奥深い話を聞ける授業です。
とてもおもしろかった。いろんな偉大な?人のお話を聞けて自分の思考の幅が広がったような気がします。
毎回何かを吸収したいと腹に決めている人間でないと、無意味な授業であるかもしれません。バカはよく、この授業が無意味だとギャーギャーうるさいが、確かに彼らにとってはホントに無意味な授業なのだと思う。ちなみに、毎週2000字のレポートをかかされますが、思考を整理するのにはとても有用な課題であって、妥当な課し方だと思っています。
化学
授業行ってないけどSが来たので良き。
化Aの試験は考察をさせてくれるタイプだったので好きでした。化Bの試験はパズルっぽい感じで楽しかった。
化学って式変形〜〜って感じっていうよりはむしろ、結果に対して考察に考察を練る、という形で思考を営むので好きです。(偏見かも)
数学I (微積)
ε-δ 論法をやらないのが少し痛いが、とてもおもしろかった。
そこ以外は普通の大学と対して内容は変わらないと思う。
英語
大学の英語の授業って基本的に受験と違って生ぬるいので良き。
英語で映画見たり、英語でしゃべったりするだけです。
生の英語に触れる機会が週に一回あるだけでもありがたい限りです...
総合教育セミナー: Murakami Haruki
村上春樹を英語で読む授業です。とてもおもしろかった。
つい先日も村上春樹に直でインタビューしたと嬉しそうに語る、村上春樹オタクのネイティブの教授と、ひたすら村上春樹について語る、そんな授業です。
村上春樹の文学論、村上春樹の人生、表現技法、フロイト的視点から見た村上春樹、メタファーに対する解釈、様々なことを英語で議論し合います。(クラスには生徒が2人しかいなかったので議論と呼べるかは不明ですが...)
英語に自信がなかったのですが、教授がとても優しかったので、僕の拙い英語でもやっていけました。先生に感謝です。
心理学
主に脳と心に関する授業です。脳の病気というリアリスティックな問題から、思考やひらめきとはなんぞや?という精神構造の問題にも焦点を当てていて面白かった。
母親が脳腫瘍で亡くなっていることから、脳の病気についてとても関心があったのと同時に、機械学習に興味があることから精神構造についても興味があって、自分にとってドンピシャの授業だったかなと思います。
ですが、僕は閉鎖的ですぐには外に出られないあの教室の構造が苦手すぎてあまり授業に出ませんでした...
それでもテストは簡単で満点近くとれたので、優しい先生に感謝。
生物
普通に面白いです。
こんな精巧な、原子レベルの身体の仕組みが自然淘汰と突然変異による偶然性によって生み出されるとは信じられないですよね。
上に書いた通り脳科学に興味があるので、とても興味をそそられる科目です。
ちなみに授業は受けたことないです。
『読んだ本』~ 少なく読み、多くを考える。~
ここからは僕が一年間で読んできた本たちを紹介したいと思います。
ですが、ただ紹介するだけではアレなので、軽く内容に触れてアウトプットでもしてみようかなと思います。
寺田寅彦『寺田寅彦随筆集』
日本の悪しき文化、"文系"と"理系"の垣根を超えたような存在の寺田寅彦先生。
僕浪人してるんですけど、その時受けた大学でよく寺田寅彦が題材になっていた気がします。たぶん入試の過去問か予想問題かなんかでこの人について調べるようになったような。
図書館で借りたので、これは僕のメモ帳から引っ張り出してきた言葉なのですが、
興味があるものを片っ端から貪り、飽きたら読むのをやめればいい、
つまらないと思ったものを読み返してみると意外とおもしろかったりするものだ。純粋に読みたいという精神というものはつまり、自分の体が欲している証拠なのである。
こういう趣旨の文章があって、とても心に響きました。
また、次のような言葉も登場します。
少なく読み、多くを考える。
これはショーペンハウアーが著書「読書」において語っていることと似ているような気がします。
寺田寅彦「思考を重視せよ。」
俺「はいわかりました寺田先生!」って感じですね。
 (岩波文庫)")
Nir Eyal『Hooked』
これは、人間が如何にSNSにハマっていくのか、ということが題材となった本です。自己に対しての警告と戒め、そして単純に興味深かったので買いました。
あとたしか、日本語訳があったのですがAmazonのレビューで原文を読んだほうがいいくらい訳が酷いと酷評されていたので、English Editionを買ったと記憶しています。
本来別に目的があってSNSを開いていたはずが、いつの間にかSNSそれ自体が目的となっていて、依存の心理サイクルにどんどんハマっていく、そのような心理構造について深く説明されている一冊です。おすすめです。
")
Peter Theil 『Zero to One』
PayPalの共同創業者Peter Thielが書いた本です。タイトル通り、0から1を生み出すような企業をどのようにして作り上げていくのか、というテーマで書かれています。
とりあえず、独占独占!って感じが全面に押し出されている本なのですが、次の文章がとても印象深かったですね。
So why are economists obessed with competition as an ideal state? It's a relic of history.
Economists copied their mathmatics from the work of 19th-century physicists: they see individuals and businesses as interchangeable atoms, not as unique creators.
Their theories describe an equilibrium state of perfect cometition because that's what's easy to model, not because it represents the best of bussiness.
(中略)
in business, equilibrium means stasis, and statis means death.
まあ言ってしまえば、何回も聞いたことあるようなお話ですが、Peter Thielが言うと、とても説得力がありますよね。
ちなみに英語のレベルはかなり高くてとても苦戦します。もう一度日本語で読み返したいなって思ってます。

Zero to One: Notes on Start Ups, or How to Build the Future
- 作者:Blake Masters,Peter Thiel
- 出版社/メーカー: Virgin Books
- 発売日: 2015/06/04
- メディア: ペーパーバック
エリック・リース『リーンスタートアップ』
タスクを細分化し、タスクに対して常にフィードバックを得ることで、高速にPDCAを回していけるので、時間リスクを極限まで減らせるよね、というお話です。
面白いしとても読みやすかった。特に、著者の具体的なエピソードと後悔、改善のプロセスが明確にかかれていたので、著者の主張がすんなり頭に落ちていきましたね。
案外、学生の時に読むべき一冊なのかもしれません。

武藤滋夫『ゲーム理論入門』
経済学に興味があって、前々からゲーム理論を学んでみたいと思っていたので、この本を買いました。ノイマンすげー!って感じです。ゲーム理論は応用性が高いらしく、いつかまた別の分野でゲーム理論と出会うのかもしれません。
なんだろう、B2になったらもっとゲーム理論を深堀りして行きたいです。
")
村上春樹『夜のくもざる』
僕はこの短編集に登場する「ドーナツ化」という短編がすごく好きですね。
3年間も付き合い、婚約までしていた恋人が、ある日突然「ドーナツ化」してしまう、そんなお話です。
「あなたにはまだわからないの?」とドーナツ化した恋人は言った。
「私達人間存在の中心は無なのよ。なにもない、ゼロなのよ。どうしてあなたはその空白をしっかり見据えようとしないの?どうして周辺部分にばかり目が行くの?」
どうして?と質問したいのは僕の方だった。どうしてドーナツ化した人々はそのように偏狭な考え方しかできないのだ。
〜村上春樹「夜のくもざる」p55, 56〜
ドーナツ化した恋人は言います、どうしてその空白を見据えようとしないのか、どうして周辺ばかりに目が行くのかと。
でも考えてみてください、ドーナツの穴を支えているのはその周辺そのものなのです。ドーナツの真ん中はそれ単体では存在できない。あの円周があってこそ穴が存在するんです。(パクパクまわりを食べちゃったら、穴がなくなっちゃいますよね?)
周辺=風体を飾るのをやめて内側と向き合う、もしくは周辺=風体ばかりに目を向ける、そのような二元論的な考え方はやめて、ドーナツそのものを見つめなければならない、読んでいてそう思いました。おすすめです。
")
村上春樹『うずまき猫の見つけ方』
「通信販売のいろいろ、楽しい猫の「食う寝る遊ぶ」の時計」というエッセイにでてくる「小確幸」のお話が好きです。
生活の中に個人的な「小確幸」(小さいけれども、確かな幸福)を見出すためには、多かれ少なかれ自己規制みたいなものが必要とされる。
〜村上春樹「うずまき猫の見つけ方」p126〜
なんだろう。胡散臭いですが、幸福って結局そういうものですよね。何事も「刺激性↔マンネリズム」というフレームに幽閉されている。欲しい物なんてひとたび手に入れてしまえば、すぐさまマンネリズムが訪れ、欲求の波も減衰していく。
欲望と幸福とマンネリズムというものは三位一体なんですよね。
ですが、それらを三位一体として捉えることに、とてつもなく重要な意味合いがあるように僕は感じます。三位一体に捉えるとはそれらをまるごと、メタ的・マクロ的に捉えるということです。そうした受容の産物として「小確幸」というものが存在しうるのではないでしょうか。
")
村上春樹『ランゲルハンス島の午後』
村上春樹のエッセイ集です。
その中でも「哲学としてのオン・ザ・ロック」というお話が僕は好きです。
サマセット・モームの「どんな髭剃りにも哲学がある」という言葉を引き合いに出し、オン・ザ・ロックの哲学性について語ります。
僕だって言わせてもらえば「どんなRedBullにも哲学がある」そう、自信をもって言い切れますね。
")
村上春樹『アフターダーク』
なんだか、感想として書くことがなさそうなので、すでに読んだ人向けに解説でも書こうかなと思います。
アフターダークというタイトルですが、決して明るい話でもなければ、わかりやすい形での救済をテーマにした物語でもありません。そもそも、アフターダークと評しているのに、作中の描写はすべて深夜に起きた出来事なのです。この作品は、おそらく2つのテーマをもっていて、①片方はタイトルの通りアフター・ダーク、つまり「精神的闇、天体的闇が過ぎ去った後」について、②もう一つは「アフター・デタッチメント」、つまり「デタッチメントからコミットメントへと移行する物語」についてだと思っています。
特徴的なのは登場人物の対比構造ですね。
エリ ーーー マリ
白川 ーーー 売春婦
何か ーーー コオロギ
この作品では、上記のような対比構造をもっていると考えられます。
左側が多義的にDarkを意味していて、右側は多義的に弱者を意味しています。
白川は潜在意識に闇を抱えている。ここで特徴的に描かれているのが、白川がただの一般人、社会人であるという点です。おそらく村上春樹は、ごく平凡な社会人、一般人であっても、どのような形であれ心の闇を抱えており、その闇は些細なきっかけから爆発してしまう=実際の行動を引き起こしてしまう可能性があるのだ、ということを書きたかったのでしょう。そして、そのダーク性は一生白川にまとわりつくことになります。これらの点がテーマ①に関わっている気がします。思い返せばこのサブテーマの設定は、「かえるくん、東京を救う」にとても似ていますね。
そして、同時にエリも深い闇を抱えています。作中ではその闇について、明確には明かされていません。そして、その深層的な闇は、マジックリアリズムという手法を用いて、空間に投影されています。具体的には、エリの部屋とTV画面の向こう側の世界のことですね。この作品が2.5人称?という設定をとっているのは、この深層心理を空間に落とし込んでいるのを際立てるためでしょう。そして、エリの潜在的な闇と白川の潜在的な闇は、一見異なるように見えますが、どちらも心の同じところから発されている。その点、どちらも同じ闇なのです。そのため、白川の世界とTV画面の向こう側の世界はリンクしているのですね。
テーマ②についてですが、おそらくマリはエレベーターの事件以来ずっと、エリから逃げ続けて来たんですね。つまり、ずっとエリに対してデタッチメントを極めづつけてきた。それゆえ、マリは夜中家を出てデニーズに引きこもり、ついには中国へ留学しようとしているのでしょう。
しかしコオロギのセリフを聞いて、マリはコミットメントへ舵を切ることを決めました。
「ときどきね、自分の影と競争しているような気がすることがある」とコオロギは言う。
コオロギの言葉を借りるのなら、エリはマリに対して影のような存在なのでしょう。つまり、二人は切っても切れない関係なのですね。それにも拘らずマリはデタッチメントを続けてきた。そのことにマリは気づいたのでしょう。作中終盤、マリはエリと共に寝てしまいますが、ここにコミットメントの兆候が見て取れます。
何かに対して ー それが何なのか具体的にはわからないのだけれど ー ひどく申し訳ないような気持ちになる。
エリとマリの距離が離れていったのは、必然でも偶然でもなく、マリにも責任がある。そしてマリは、エリの心の闇を生み出した原因の一端を担っているのではないのかと感じているのでしょう。そして、この不可逆的コミットメントへの舵切りが果たして良かったのか、この行動が正しい行動であったのかマリは不安になります。そうした心情が表れたセリフなのでしょう。
絶対に読んだほうがいいです一作です。おもしろいし、短くて読みやすいのでとてもオススメです!
")
村上春樹『海辺のカフカ』
傑作です。おもしろい!
海辺のカフカのバックグラウンドにはギリシア神話、ギリシア悲劇が絡んでいます。ですが、そんなのはもう一目瞭然です。というのも、カフカくんはオイディプス・コンプレックスを彷彿させますし、カーネル・サンダースなんて、どっからどうみてもデウス・エクス・マキナ(機械仕掛けの神)です。一目瞭然といいながら、気づいたときは興奮しちゃいましたね。
ぼくにとっては次のセリフがとても印象深いです。
「すべては想像力の問題なのだ。僕らの責任は想像力の中から始まる。イェーツが書いている。In dreams begin the responsibles ー まさにそのとおり。逆に言えば、想像力のないところに責任は生じないのかもしれない。このアイヒマンの例に見られうように。」
このセリフからは2つの意味合いを汲み取ることができます。
一つは、「夢というものはフロイト的思考にも見られるように、潜在意識、無意識によるものである。そうである以上、夢というものにも責任が生じるのである。」ということ。
もう一つはハンナ・アーレントが指摘したことと全く同じことです ー つまり、平凡性、無思想性=創造性を欠いた状態の人間はすぐにでも悪となりうる、そして彼らは無自覚に悪を遂行する、ということです。
急にこういうのぶっこんできたりするんですよね、村上春樹って。
意外と奥深いです。おもしろい!
 (新潮文庫)")
 (新潮文庫)")
村上春樹『ダンス・ダンス・ダンス』

五反田君はとても評判の良い若手俳優です。学生時代、五反田君と知り合いだった主人公は、当時の五反田君のありとあらゆる動作が、とにかく映画の主人公のように美しいと語っていますが、この作品ではとにかく、五反田君が非常にこだわって描写されている印象を受けました。
作中、五反田君は演技と自分の本質の境目がわからなくなると言います。(ちなみに、同じようなことが、W.ベンヤミンの「複製技術時代の芸術」にも書かれている。)
五反田くんには『「本質」↔「形式的行為」』という作者の設定した意図的な構図を感じ取ることができます。
また、この作品は高度資本主義経済のありとあらゆる側面を如実に写し取ろうとしているような感じも伺えます。たとえば、「いるかホテル」が高度資本主義によって建て替えられたりしますが、モロにこのようなセリフも登場します。
それで僕は無駄というものは、高度資本主義社会における最大の美徳なのだと彼に教えてやった。
(中略)
無駄というものは矛盾を引き起こす燃料であり、矛盾が経済を活性化し、活性化がまた無駄を作り出すのだ、と。
〜村上春樹「ダンス・ダンス・ダンス」上 p57〜
さらに、何度も強調される言葉として「文化的雪かき」という言葉が登場します。
女性誌というのはそういう記事を求めているし、誰かがそういう記事を書かなくてはならない。ゴミ集めとか雪かきとかと同じことだ。
(中略)
僕は三年半の間、こういうタイプの文化的半端仕事をつづけていたた。文化的雪かきだ。
〜村上春樹「ダンス・ダンス・ダンス」上 p31, 32〜
これらからも『「本質」↔「形式的行為」』という構図を読み取ることができますね。
僕的には、『「本質」↔「形式的行為」と、その間に存在する「雑多性」』というスキームが、この作品の一つのサブテーマとして設定されているように感じます。
この形式性、本質性、雑多性の枠組みが非常にうまく絡み合って、作品に絶望感が生み出されているのでしょう。とてもおもしろかったです。

村上春樹『色彩を持たない多崎つくると、彼の巡礼の年』
これは読んだことがある人にしか伝わらないと思うので、そのような人たちに向けて書くことにします。
しかし射精を実際に受け止めたのは、シロではなく、なぜか灰田だった。気がついたとき女達はもう姿を消し、灰田がそこにいた。
〜村上春樹「色彩を持たない多崎つくると、彼の巡礼の年」p135〜
上の描写はおそらく、夢ではなく現実世界における出来事なのでしょう。
アカ・アオ・シロ・クロ。多崎つくるを除いて、唯一濁りだという認識が可能な色は灰色を名前に冠した灰田だけです。つまり、文字通り異色=バイセクシャルであったのだと考えられます。灰田の六本指の話は、自分が他の者と異なるというシグナルであったのだと僕は思ってます。
この小説は謎解き要素が強すぎて、あまりメッセージ性を感じなかったように記憶していますね。。。
")
村上春樹『風の歌を聴け』
恥ずかしながらデビュー作を読んだことがなかったので、読んでみました。
この作品は断章形式になっていて、一回読んだだけじゃなにの意味もわからない、
というか、これを読んで何ヶ月も経った今でも全然理解していないような気がします。。
とりあえず鼠が主人公のアルターエゴであること以外、ここに書けることはないですね、、
")
村上春樹『村上春樹 雑文集』
村上春樹のエッセイやインタビューやら短編やらが、タイトル通り雑多な感じでいろいろはいってる文集です。
その中でも僕は「自己とは何か (あるいはおいしい牡蠣フライの食べ方)」というエッセイがもう狂おしいほど好きなんです。
村上春樹がある質問に答えるという話を副軸に構成されているエッセイです。
村上春樹は次のような質問を受けます。
先日就職試験を受けたのですが、そこで「原稿用紙四枚以内で、自分自身について説明しなさい」という問題が出ました。
(中略)
もしそんな問題を出されたら、村上さんはどうしますか?
すると村上春樹はこう答えるのです。
こんにちは。原稿用紙四枚以内で自分自身を説明するのはほとんど不可能に近いですね。
(中略)
ただ、自分自身について書くのは不可能であっても、たとえば牡蠣フライについて原稿用紙四枚以内で書くことは可能ですよね。
だったら牡蠣フライについて書かれてみてはいかがでしょうか。
え!!!!!っってなるでしょ?
たまらないんですよ、こういう意味わからない感じが!
春樹はその理由について次のように語ります。
あなたが牡蠣フライについて書くことで、そこにはあなたと牡蠣フライとの間の相関関係や距離感が自動的に表現されることになります。
それはすなわち、突き詰めていけば、あなた自身について書くことでもあります。それが僕のいわゆる「牡蠣フライ理論」です。
自分のことを一番知ってるのは自分であるはずなのに、自分について書けと言われたらなかなか書けない ー それは自己の行動を客観的に見ようとしているからです。だったら話は単純。主観性を全面に押し出し、間接的に自己を表現すればいいのです。
例えば、あなたが今読んでいる僕のブログは、僕の自己紹介文でもあるわけですね。思考と実際の行動を意識的に切り分けて書いているので、余計にこの性質が浮き彫りにされているのかもしれませんね。
ほんとに大好きな一作の紹介でした。
")
星新一『きまぐれエトセトラ』
星新一の短編集かと思って買ったらエッセイだった、という感じで、勘違いで買いました。でも面白かったです。
特に、「会話」というエッセイが好き。
しかし、一般に歯医者に対する評判は、あまり良くないようである。
(中略)
いったい、なぜ不評なのかと原因を考えてみて、気がついた。すなわち、会話の不足である。
これが他の普通の病気なら、診察中や治療中に、医師との会話がかわせる。
(中略)
そして、医師は答え、患者は精神的になっとくするのである。
患者というものは、内心、医師の言葉を求めているのだ。
〜星新一「きまぐれエトセトラ」p35〜
なんとも不思議な文章であります。ほんとうか?という気持ちと、なるほど〜という気持ちがこんなにも両立する文章、なんだか気持ち悪いです。
まあそのことは置いておいて、歯医者の特異性に気づいた星新一はさすがです。
")
加藤典洋『村上春樹の短編を英語で読む』
まだ読んでる最中ですが、面白いです。
")
船木亨『いかにして思考するべきか』
いやぁ、この類の本はとても読むのに疲れますし、なによりもまとまって読む時間が取れない。 話の流れを整理するのにとても時間がかかるんですよね。「思考」について興味があったのでこの本を買ったのですが、挫折気味の一冊です。

なんかメモってあったけど、正直何をメモってるのかも忘れてます。一章について軽く説明すると、Cogito, ergo sumってあるじゃないですか。これって論理的帰結ではなく、「懐疑」自体を懐疑する、というある種のトートロジーを集結させるための、いわば「公理」なんですよね。そして、デカルトの言うコギトとは "思考する<わたし>"というよりはむしろ、"思考しているという意識を持つことだ"、と著者は言います。
そうして世界と<わたし>は分離されていくわけですが、ここで留意しなければならないことが一つあります。それは、<わたし>の実存と眼前の物体の実存とは構造が違うよ、という点です。物体の実存は主観の中心点である<わたし>による感覚的判断によって規定される。しかし、感覚というものは誤謬の源であり、明確な判断の物差しとは成りえない。そこで、世界の中心点である「神」から見ることで、物体の実存を主観性と切り離して規定していく必要があると言うんですね。さらにその神からの視点を追体験するための道具として、デカルトは数学を用いたと。
ちなみにデカルトは神は善良であるという理由から、数学を用いて物体の存在を規定しようとしたらしい。
春休みはまとまった時間が取れるので、是非読破したいですね。

許成準『天才たちのライフハック』
青色LEDを開発した中村修二教授の「与えられたものをそのまま使わない」というライフハックが印象に残っています。
彼は、実験するときに実験装置を改造して使う習慣をもっていた。中村は自著で、日本の研究者たちが設備をカスタマイズせず、そのまま使うことを批判している。
(中略)
彼が青色LEDの開発に成功したのは、他の研究者たちが研究していなかった「窒素ガリウム」という素材を使ったからだったが、当時市場には、これを加工できる装置は存在しなかった。
(中略)
中村は現場で磨いた技能を使って、「窒素ガリウム」を加工できるように実験装置を改造した。
〜許成準「天才たちのライフハック」p126〜
おもしろいですよね。発想がエンジニア的なので胸が踊ります。

スティーヴン・ホーキング『ホーキング、自らを語る』
かの有名なスティーヴン・ホーキングの自伝です。ホーキング博士の人生自体がとてもおもしろい人生だなと思いました。中でも次の言葉がとても胸に響いています。
疫病はさして学究生活の妨げにはならなかった。むしろ、ある意味では得をしたように思う。学生相手に教室で講義をしたり、時間の浪費でしかない不毛な議論や委員会に出たりする義務を免れて研究に専念することができたのはありがたかった。
豊かに恵まれた人生だった。障害者は自分の欠陥に邪魔されない仕事に打ち込めばいい。できないことを悔やむには及ばない。

クレア ウィークス『不安のメカニズム』
気分が悪いな、ここで吐いたらどうしよう、だとか、一般に身体現象が不安を駆り立てると人々は考えますが、実は逆も然り。思考による不安がアドレナリンの分泌を促し、さらなる身体現象を促進するらしい。
従って、ある不安に対して身体現象が促進されるような脳内回路が一度完成してしまえば、不安のサイクルにどんどんハマっていくらしいです。
そういった人はどうすればいいのか。筆者曰く、解決策は唯一つ ー 薬物治療のような物理的治療ではなく、精神的な治療であると。
どんな人間も気分が悪くなったら不安になります。ですが不安障害の人は正常な人間の頭にも普通によぎるような不安に対し、過剰に反応するような脳内回路が出来上がってしまっているのです。彼らは、その回路のサイクルを徐々にほどいてやる必要がある、そのためには精神的に治療しなければならない、そう筆者は言うのです。
とてもためになった一冊でした。
")
ロルフ・ドベリ『Think Clearly』
52個もの様々な考え方について書かれている本です。「よりよい人生を送るための思考法」とかいうクソ胡散臭いサブタイトルがつけられていますが、普通に良本でした。
特に3番「大事な決断をするときは、十分な選択肢を検討しよう」38番「自分の頭で考えようー イデオロギーを避けたほうがいい理由 ー 」51番「自分の人生に集中しよう」が自分にとって大事だなと思いました。
3番→ 確率論を主軸に生きていく以上、サンプル数を増やす必要がある。「秘書問題」を想起せよ。とても見落としがちな事実であります。
38番→①規模のでかく、②あらゆる事象に対して答えがあり、③反論の余地がなく、④不明瞭な意見のことをイデオロギーと呼ぶ。我々の思考は基本的に、属するコミュニティーの意見へ個人的重み付けを付したものの総和である。それゆえイデオロギーには気をつける。アンダーラインを引いたところがとても印象的です。
51番→古代ギリシアの「アタラクシア」を想起せよ。自分の制御できるモノとできないモノを切り分ける。「7つの習慣」にも同じような趣旨の文章が登場しますよね。(たしか)

エリック, ジョナサン, アラン『How Google Works』
とてもおもしろかった。Googleに関する様々なtipsが散りばめられてあります。引用したい箇所が多すぎて選びきれないので内容には触れませんが、絶対に学生のうちに読むべき一冊です。おすすめ。
 私たちの働き方とマネジメント (日経ビジネス人文庫)")
How Google Works(ハウ・グーグル・ワークス) 私たちの働き方とマネジメント (日経ビジネス人文庫)
- 作者:エリック・シュミット,ジョナサン・ローゼンバーグ,アラン・イーグル
- 出版社/メーカー: 日本経済新聞出版社
- 発売日: 2017/09/02
- メディア: 文庫
ヴォルターベンヤミン『複製技術時代の芸術』
「複製技術時代の芸術」 を読む勉強会へのお誘いをいただいたので、初めてベンヤミンの著書を読んでみたのですが、ベンヤミンってとても博識でおもしろ人ですね。主張もおもしろかったです。個人的には以下の文章たちがとても印象に残っています。
つまり、映画の気晴らし的な要素は、見ている者にガクッガクッと断続的に迫ってくる場面やショットの移り変わりにもとづいている。映画が上映されるスクリーンと絵画の描かれるキャンヴァスを比較してみるとよい。後者は見るものを瞑想へといざなう。キャンヴァスを前にする時、見るものは連想が流れてゆくままに身をまかせることができる。映画の映像を前にするときにはそうはいかない。
(中略)
映画の映像は固定しておくことができない。
(中略)
デュアメルはこういった事情を次のようなコメントで表している。
「自分が考えようと思っていることをもはや考えることができない。動く画像が私の思考の場を絞めてしまうのだ。 」
と書いてありますが、その後ベンヤミンは
大衆は気晴らしを求めるが、芸術はそれを見るものに精神の集中を要求するのだ...
(中略)
このことはより仔細に見ておく必要がある。
と書き、
芸術作品を間にして精神集中する者はそのなかに沈着する。
気が散った大衆のほうでは、芸術作品を自分のうちに沈着させる。
と、芸術作品における2つの認知形式を明確化しています。なんだか表現がおもしろいですよね。
気の散った状態[気晴らし]で受容することは、芸術のあらゆる領域でますます明確に現れており、統覚の徹底的な辺の兆候となっているが、そういった受容にとってのトレーニングの道具となっているのが映画なのである。
また、総括として上のような文言が書かれており、なるほどなと感心しました。
ベンヤミン案外おもしろかったので、春休みに、このアンソロジーにコレクトされてある「言語一般について、また人間の言語について」を読んでみたいなと思ってます。
")
掌田 津耶乃『Firebase入門』
お仕事で使いました。awsの社員さんと合うと怖くて泣いてしまいます。

Pete Goodliffe『ベタープログラマー』
いやぁ、テストコードきちんと書かないといけないなと思いました。
TDDスタイルは、たまにしか取らないので、それじゃだめだなぁ、てかTDDじゃなくてもテストコードくらいきちんと書こうや、って感じで反省してます。

ベタープログラマ ―優れたプログラマになるための38の考え方とテクニック
- 作者:Pete Goodliffe
- 出版社/メーカー: オライリージャパン
- 発売日: 2017/12/15
- メディア: 単行本(ソフトカバー)
矢沢久雄『コンピューターはなぜ動くのか』
教養的なものを身につけたくて買いました。
おもしろかったです。

オライリー出版『アルゴリズムクイックリファレンス』
自分はまだまだド素人でアルゴリズムの知識があまりないので、この本を買いました。あまり評価は高くないようですが、僕としてはある程度の量のアルゴリズムを体系的にまとめてくれている点は良いなと思いますし、タイトル通りクイックリファレンスとして、なんども一冊の本で復習しながら、知識を定着させていきたいという目的があったので、この本を選びました。できれば春休み中に読み終えたいですね。

- 作者:George T. Heineman,Gary Pollice,Stanley Selkow
- 出版社/メーカー: オライリージャパン
- 発売日: 2016/12/24
- メディア: 単行本(ソフトカバー)
シェイクスピア『ハムレット』
これぞ古典!!!って感じです。実はアガメムノンなども読んだりしていたのですが、ハムレットは比較的最近(?)書かれたモノだということもあり、断然アガメムノンより読みやすかったです。てか、言ってしまえば普通の小説よりも全然読みやすいです。
毎度注釈が下の余白に載っていて、当時の時代背景や、暗喩、言い回しの真意についての訳者の説明がとてもおもしろかったです。
")
石川啄木『一握の砂』
よ 会 長
ろ ふ く
こ ご 長
び と く
を き 忘
も れ
て し
水 と
の 共
音 に
聞
く
恋 熱 や
し て は
て る ら
み を か
た 頰 に
し 埋 積
む も
る れ
ご る
と 雪
き に
草 息 何
原 き が
な れ な
ど る し
を ま に
で
駆
け
出
し
て
み
た
く
な
り
た
り
言い回しが好きだったり、表現が美しかったり、あ〜わかるなその気持ち、みたいな感じだったり。僕の好きな歌たちです。

『終わりに』 ~ 局所解とB2 ~
大学一年生として過ごした2019~2020の僕の行動は、ある意味失敗だったかなと思います。
というのも、僕はあまりにも自分の進捗を重視しすぎていたし、友達との付き合いや恋愛、サークルなどといった社会性をあまりにも捨象していました。
もちろん、こうした生活を送ることがプラスに働いた部分も大きい ー しかし、前述の導入部分でも書いたように、生活を送っていく中で、それらの「ぼろ」は見過ごせないほど肥大化していたのです。
したがって、来年度はある程度の進捗を犠牲にしてでも、社会性を取り戻すための長い長い社会訓練の旅に出ないといけないのかな、と思ってます。(なぜそれほど長い旅が必要なのかは、僕と僕の元カノのことを知っている人ならうすうす気づいているのかもしれませんが。)
しかし、それと同時にやはり、この「吸収と苦闘の一年」は成功だったと言えるのかもしれません。いや、より正確な言葉を用いるならば、「必然的で絶対的に必要であった」のでしょう。
僕はこの一年、僕が高校の時に望んでいた"理想の大学生活像"みたいなものを完璧に体現しているような気がするんです。ですが、それは局所的な最適解であって、大学生活全体としての最適解ではなかった。
想定している解が局所的かどうかは、実際にそこに立ってみて、ある程度先の形までもを自分で見てみる必要がある。そうして初めて、それがどうやらグラフ全体としての最適解ではないことが確認できるんです。
僕はその「思い込んだ幻想の最適解」の上に、実際に立ってみなければならなかった。そのプロセスこそがこの2019~2020の1年です。
デタッチメントではなくコミットメントへ、局所的最適解ではなく大局的最適解へ。B2の目標です。